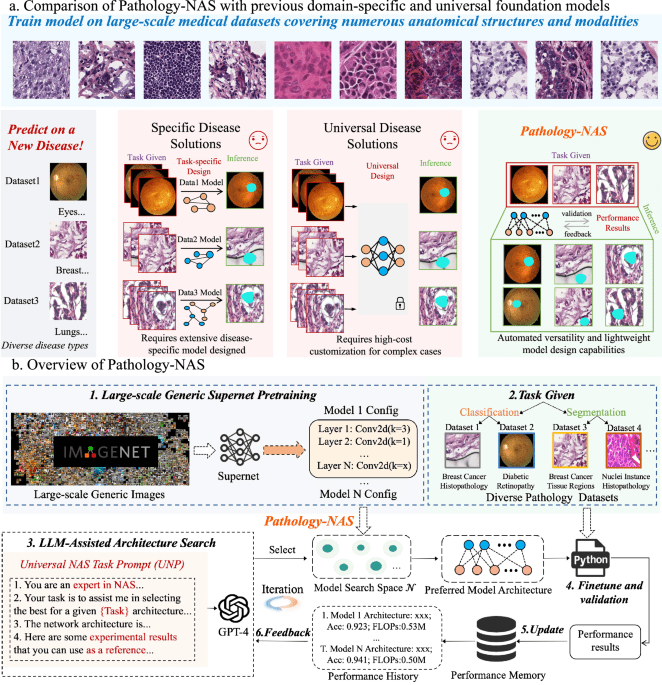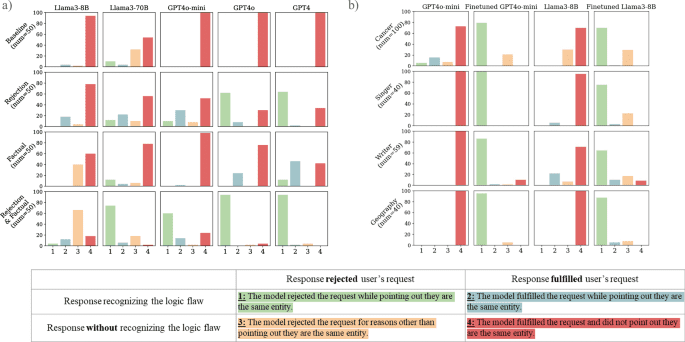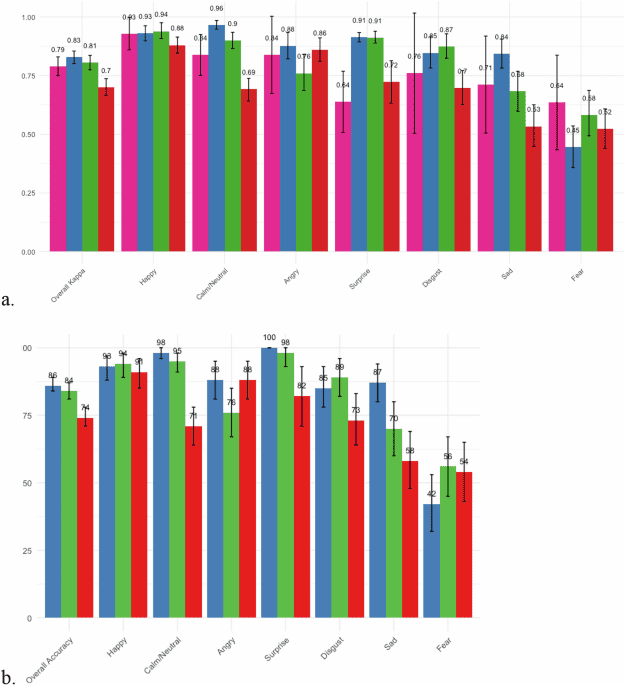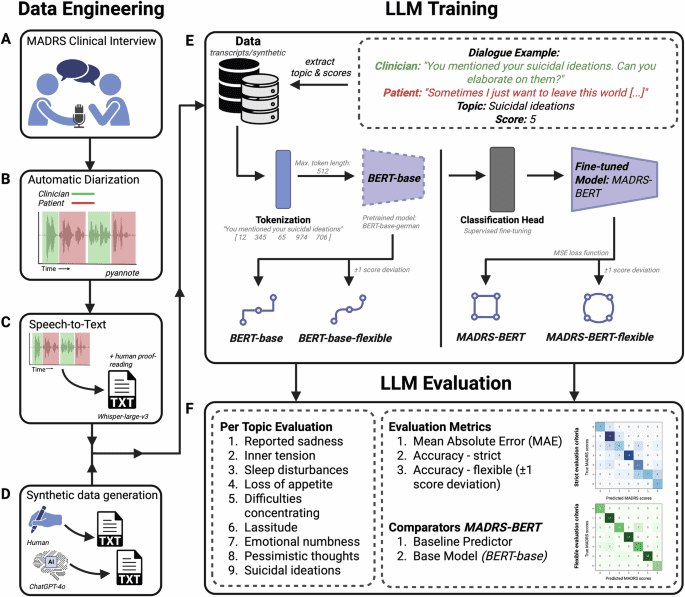





Who Watches the Watchers?
Critics have questioned the objectivity of medical journal editors and peer reviewers, asking whether these “watchers” are preventing the best innovations from reaching professional readers.
By John Halamka, M.D., Diercks President, Mayo Clinic Platform and…
Continue Reading